False advertising
10/6/2023 ☼ not-knowing
This essay is different from the ones that came before it in this series on aspects of not-knowing. The main difference is that I’m very actively working out the ideas below. An earlier version appeared in my newsletter on 17.5.2023; the version below has been revised and expanded with contributions from friends and discussants in my monthly public discussion series on not-knowing.
If you’re new to not-knowing (a concept different from both formal risk and from uncertainty), it might help to take a look at my introduction to not-knowing, my overview of overloading and appropriation and the updated diagram below before reading on.
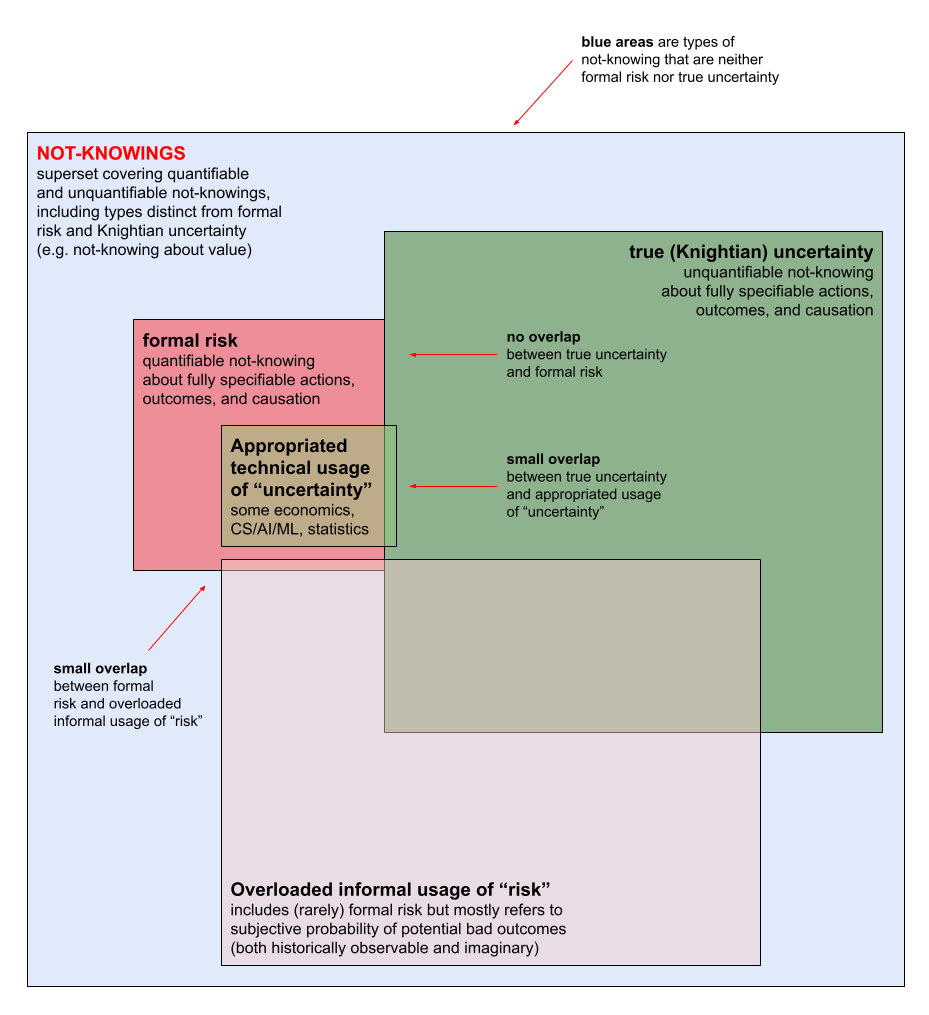 How not-knowing overlaps (or doesn’t) with formal risk, true uncertainty, overloaded informal “risk,” and appropriated technical “uncertainty.”
How not-knowing overlaps (or doesn’t) with formal risk, true uncertainty, overloaded informal “risk,” and appropriated technical “uncertainty.”
Some caveats:
- I’m not claiming expertise in computer science, economics, artificial intelligence, or statistics. If you are an expert in one of these fields and what I’ve written below seems wrong, please let me know. I’d especially appreciate it if you’d explain it to me in as simple and non-domain-specific language as possible. Contact details at the bottom of this page.
- I’m not claiming that every technical usage of “uncertainty” in CS/AI/ML, economics, and psychology has appropriated the word in the sense I describe below. Some (often quite influential) approaches in these disciplines are doing this appropriation, but there are — there must be! — people using “uncertainty” in the correctly defined sense of the word.
- I’m not claiming that the ideas presented below are correct and fixed. I’m still making up my mind and looking for new input. My criticisms of methods, conclusions, and syntheses below are provisional. I especially want to make this essay better with the help of comments — so tell me where I’m wrong or need to be clearer!
With all that out of the way, my argument begins from the position that the word “uncertainty” is appropriated when it is used in a way that does violence to its meaning as unquantifiable not-knowing about a situation (i.e., Knight’s definition). For Knight, true uncertainty is not-knowing that is “not susceptible to measurement and hence to elimination.” True uncertainty is defined by the unquantifiability and unmanageability of not-knowing (as opposed to risk, which is not-knowing which can be quantified and thus managed and eliminated).
The appropriative strategy seems to be to use “uncertainty” to describe a form of not-knowing that can be quantified and thus can be made controllable. Examples from machine learning might illustrate what I mean by this.
Appropriation of “uncertainty” in machine learning (ML)
One ML task is to develop a machine model that can evaluate a set of data (e.g. a bunch of photos) and put labels on them (e.g. “this photo is of a mug,” “that photo is of a twig”) — an image classification model. The fewer the errors in the output (e.g. appending the label “this photo is of a mug” to a photo of a twig), the better the model. Because the model is trained on some data (e.g. a dataset of images of mugs and twigs that has been labeled by a panel of humans) and then used on other, different data (images of things that could be mugs and twigs that need labeling), there can never be 100% certainty in a model’s labeling outputs.
When it comes to using a model, it’s important to know how much to trust the model’s outputs. This is particularly true if the outputs will be used to take actions that have important implications in the real world — such as an image classifier that is used by self-driving cars to detect and avoid traffic hazards. This model will have been trained on a dataset (say, of images of traffic hazards labeled by humans) and then used to label images taken from a self-driving car’s video camera. There won’t be 100% certainty in whether the model will correctly label a traffic hazard as “traffic hazard.”
In the ML context, this lack of 100% certainty would be labeled “uncertainty,” but what it actually seems to be is [not-knowing whether the model’s output is objectively correct or not, given a restricted range of assessments of correctness and strong assumptions about the similarities between training data and actual data being processed by the model].
This type of not-knowing doesn’t sound like either the narrow definition of formal risk or the overloaded informal definitions of risk, which may be why the AI/ML industry has decided to call it “uncertainty.” And this type of not-knowing about a model can be estimated and quantified (“uncertainty quantification”), thus permitting the model to be operationalised. One currently fashionable family of approaches for “quantifying uncertainty” in ML is conformal prediction, which “uses past experience to determine precise levels of confidence in new predictions.”
In fact, there are at least four different kinds of partial knowledge situations ML runs into:
- Uncertainty from poor data quality: Model builders and users need to understand the quality of the data (e.g., incomplete or otherwise biased datasets) on which models are built so that they can interpret the outputs of these models. This may not be true (Knightian) uncertainty, especially for datasets where the range of possible values is constrained by design to a fully specifiable set.
- Uncertainty from model opacity: The trained model itself introduces uncertainty, especially when it is a black box, because the mechanism by which model outputs are produced is not clearly understood. Again, this may not be true uncertainty, though the underlying model when revealed may prove to be beyond human capacity to comprehend.
- Uncertainty from inherent ambiguity in data: This seems like a type of epistemic true uncertainty. This type of uncertainty seems correlated with the requirement for representing complexity in the data domain. Concepts and distinctions ramify and increase in number as the complexity of what needs to be represented/communicated increases. Names of colours and names for numbers (countable units) were two examples that came up in discussion. This is related to the underlying problem of how people who don’t share the same subjective reality can communicate. This pattern (complexity of terminology being driven by requirement for representing/communicating complexity in a domain) also seems clearly connected to the need for more nuanced ways to describe and talk about about different types of not-knowing.
- Uncertainty from subjectivity of experience: This seems like another type of true epistemic uncertainty. Current ML approaches depend (either implicitly or explicitly) on analyses of the names given to things/concepts. This conceals true uncertainty about models that results from the distinction between perception of phenomena and names for phenomena, the fact that language (in the form of names for things) partly determines what we perceive, and the fact that different individuals have different ranges of perception (the idea of an individual- or species-specific sensorium or gamut).
[This non-exhaustive list was developed with the discussants in the fifth discussion on not-knowing.]
Of the four types of uncertainty in ML identified above, only the first two (uncertainty from poor data quality and model opacity) seem to have epistemologically viable technical solutions at the moment — and neither constitutes true uncertainty in the Knightian sense. I’m not sure that the latter two types of uncertainty in ML (uncertainty from inherent ambiguity in data and from subjectivity of experience) are given serious operational consideration at the moment.
So here’s what it boils down to more generally: You don’t know something and you want a way to calculate how to take action despite not knowing that thing. In order for the calculation to work, you have to put a number on what you don’t know. One unfancy way to do this is to say “I’m making up a number.” The fancy way is to say: “I’ve developed a very sophisticated method for putting a number on what we don’t know so we can use our other very sophisticated methods for calculating what action to take.” These sophisticated methods for putting numbers on what is unknown are sometimes billed as methods for dealing with “uncertainty” even when
- What they actually deal with is risk, or
- What they actually deal with is true uncertainty but the method consists of making up arbitrarily precise quantifications of unknown values and their probabilities of occurrence which are all of unknown accuracy.
This appropriation isn’t only happening informally in casual usage. In fact, it happens a lot in highly technical contexts. AI/ML research is one such context, but there are similar dynamics in the usage of “uncertainty” at work in psychology, economics, quantitative finance, policy, and operations management.1 Maybe more troubling: This appropriative use of “uncertainty” gains legitimacy and widespread traction from the reputability of these fields and the people who work in them.
Sure seems like a form of false advertising to me.
We need comfort — even false comfort
Humans need to know things and be certain of them. This need seems visceral, existing mostly below conscious cognition, in the realm of emotion, affect, and instinct. Maybe this is why we have such strong implicit beliefs about certainty and the possibility of being certain. It may also be why we find it so hard to change such beliefs even when faced with evidence that such beliefs are not consistent with reality.
Non-risk not-knowing (which includes true uncertainty) is intensely and viscerally scary because it isn’t quantifiable and cannot be managed away. Overloading and appropriation can both be understood as ways of managing this visceral terror of the unknown. Overloading takes lots of very scary non-risk not-knowing and labels all of it as “risk,” which is quantifiable and manageable. Very comforting. Appropriation takes specific and manageable types of not-knowing and labels them as “uncertainty,” suggesting that true uncertainty is now manageable. Also very comforting.
Both forms of inaccurate usage provide false comfort by creating the impression that unknowns are more manageable and controllable than they actually are. The words we use make us misdiagnose the situations we confront. That’s what’s happening with overloading and appropriation (the diagram at the beginning shows how overloading and appropriation relate to other types of not-knowing).
Words matter
The words we use to describe a situation of not-knowing shape how we think about acting in that situation. Both overloading and appropriation are bad because they warp how we think about acting when we face different forms of not-knowing.
If we say a situation is “risky” we tend to act using methods that are only appropriate for formal risk situations — this is bad when we use “risk” to refer to non-risk situations. Conversely, if we say a method is good for dealing with “uncertainty” we tend to think we can use it when faced with non-risk situations — this is bad when the method is actually only good for formal risk.
We need to say, as precisely and unambiguously as we can, what we mean when we are talking about the many different types of not-knowing that exist. The challenge is that our words for not-knowing — “risk,” “uncertainty,” “ignorance,” “ambiguity,” etc — are all inadequate. The best word we have for non-risk not-knowing is Knight’s definition, and that isn’t perfect either because
- It contains many types of non-quantifiable not-knowing that are different from each other, and
- It omits some forms of non-risk not-knowing entirely (such as not-knowing about relative value).
This is why I’ve been using “not-knowing” instead as a blanket term to describe all the situations of partial knowledge we face. “Not-knowing” includes formal risk, true uncertainty, and forms of non-risk not-knowing that aren’t included in Knightian true uncertainty.
From here on I’ll be deep-diving into these different types of non-risk not-knowing — my goal being to understand how each type differs in how you come to know it, relate to it, and deal with it.
For more on this, take a look at item 4 in the discussion highlights from the fifth discussion on not-knowing.↩︎