What makes us human (for now)?
18/1/2023 ☼ AI ☼ humanness ☼ meaning
tl;dr: What it means to be human is (and should be) a moving target. Lots of people are excited that we are on the cusp of building machines that have human intelligence because of what AI systems (like Stable Diffusion or ChatGPT) can now do. I argue that this excitement is misplaced because we misunderstand what human-ness is for now: the ability to create and give meaning, which we do when we decide or recognise that a thing or action or idea has value, that it is worth pursuing. So far, even sophisticated machines are only able to search for, find, and borrow meaning from humans — and we mistake this for human-ness because we are out of practice with meaningmaking.
🙏 to @bandos_1000, Erik Garrison, Paul Henninger, Nicolas della Penna, and Dan Schrage for comments and adjacent conversations. I am entirely responsible for any remaining poor thinking.
Interesting times
2022’s Big Tech News, leaving aside stuff like the crypto winter from the FTX implosion, was artificial and implicitly human-level intelligence finally arriving for the non-technical person in the street. This came in the form of AI models like GPT and Midjourney that were exposed to the lay public with natural language prompt interfaces (like ChatGPT and the Midjourney Discord interface).
These AI models are — loosely — mathematical models of the relationships in a body of content. Modeling the relationships between words, groups of words, and other things we care about (such as images) allows these models to do things like summarise documents, predict the next word in a sequence, respond to some kinds of questions, and other tasks that humans often do. The AI models of 2022 were trained on huge bodies of content, corpora of multiple petabytes (each petabyte is a million gigabytes). Apart from how genuinely cool it is that our machines can now chew up, digest, and present for interrogation genuinely enormous corpora of content, I think this went viral and became big news for three reasons.
First, the “AI” that hit the market was widely and easily accessible to non-specialist users. Users interacted with the AI models of 2022 by prompting them in ways that seemed close to natural language and — crucially — in ways that are now familiar because they map to the oracular ask-answer models of search engines and chat/messenger services. Experimenting was not limited to code nerds. And cost was not a significant barrier to non-specialist experimenting. Using these tools didn’t cost much, in some cases was free. Venture (or government) funding paid for the enormous costs of developing and training the models, and even for the machine time needed for using them. The training data for these models (stuff like responses on message boards or captions on uploaded images) seems to have been used without compensating the creators of the data. 2022 was the first year I got messages from people not in or adjacent to tech telling me, unprompted, that they’re experimenting with Midjourney or ChatGPT or whatever and Look, isn’t it cool what you can do with it!!!
Second, what hit the market was often platform technology that allowed others to develop derivative tools on top. Stuff like an online graphic design tool making it possible for its users to generate an image for editing using a text prompt to Stable Diffusion, or automating the process of summarising legal documents using GPT-3. These derivative tools make use cases explicit and demonstrate the value of the platform technology — it does the imagining for the user.
The first and second reasons meant that more regular folks played with AI models in a context that made their value clear and concrete.
The third reason really set things off though: The outputs of what all these people were playing around (Midjourney, Stable Diffusion, ChatGPT) were very often hard to distinguish from what humans could produce, as you can see in the two images below. The first is an image from Canva illustrating its Stable Diffusion text-to-image app. The second is an image from TokenizedHQ illustrating Midjourney outputs in response to prompts.
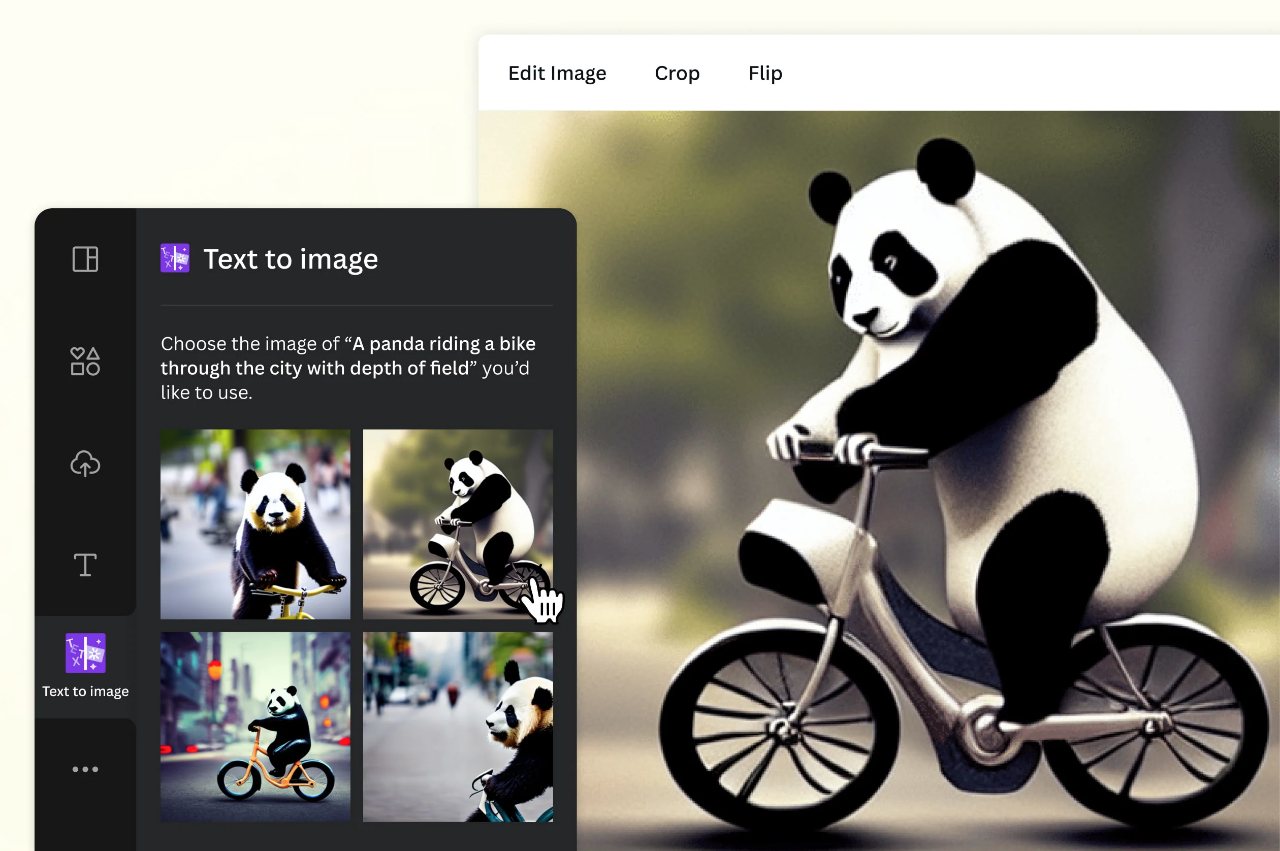 Canva screenshot of output from text-to-image app prompted with “Panda riding a bike through the city with depth of field.”
Canva screenshot of output from text-to-image app prompted with “Panda riding a bike through the city with depth of field.”
 Midjourney output prompted with “room of surgeons operating on a single pumpkin carving, surgeons crowded around an operating table stanley artgerm lau illustration, akihiko yoshida illustration, sakimichan illustration, krenz cushart illustration.”
Midjourney output prompted with “room of surgeons operating on a single pumpkin carving, surgeons crowded around an operating table stanley artgerm lau illustration, akihiko yoshida illustration, sakimichan illustration, krenz cushart illustration.”
Non-specialist usability (Reason 1) combined with good user interface layers (Reason 2) means lots of non-specialist users. When these non-specialist users (who sometimes have lower thresholds for evaluating the products of technology) interact with what’s branded “artificial intelligence” in ways that feel prosaic and everyday, they nonetheless get results that seem impossibly sophisticated, as if made by humans (Reason 3). How did the technology do that?? The contents of the black box of these AI models feels magical. (“Any sufficiently advanced technology is indistinguishable from magic.”1) This pattern [do unspecial thing ☛ get unexpectedly profound result] reliably produces the Wow, that’s so cool! reaction. That’s what made everyone want to share both the output and the “AI” platform that made it — the classic viral mechanism which made AI into Big Tech News.
Here we run into the problem.
Successful imitation is a problem for defining human-ness
One of the many underlying assumptions in the AI models that have become well-known to lay consumers is that things found together are likely to be connected, and the connection is probably stronger if you find those things together frequently. In other words, these AI models learn by finding patterns of association in masses of data, and it infers patterns from how frequently associations occur.
Text-to-image capability (the ability to generate an image from a text prompt, like Midjourney or Stable Diffusion) results from a model that has been trained on a dataset of images associated with text — such as a very large set of images with captions, alt-text, or discussions, of the sort that might be collected by a service like Meta’s Instagram or Google’s reCAPTCHA, or processed by Google for Image Search. With a large enough set of images-associated-with-text to analyse, a machine can learn that particular configurations of pixels are often associated with the word “panda”, particular configurations of pixels are often associated with the words “riding,” “a,” “bicycle” (i.e., the phrase “riding a bicycle”) when they occur in sequence like that. A model that can generate an image in response to a text prompt comes after a model that can label and thus “identify” in text an image’s contents.
Similarly, text-to-text capability (generating text based on a text prompt, like ChatGPT does) results from a model trained on a set of texts associated with other text and other descriptive information — such as a large collection of scanned and OCRed books or the contents of online discussion boards. With enough of the correct text-associated-with-other-text to analyse (for instance, a database of digitised contracts), a machine can learn that particular configurations of words are often associated with the phrase “arbitration clause,” or that some configurations of words are associated with the phrase “arbitration clause valid in the UK” but not with the phrase “arbitration clause valid in the US.” With enough of other text-associated-with-other-text to analyse (for instance, a repository of open-source code), a machine can learn that particular configurations of words are often associated with the phrase “efficient sort algorithm” or “string-matching algorithm” — because code is also “just” a bunch of words.
The AI models that went public in 2022 are the result of machines processing and learning from enormous volumes of content, much more content than any human can process and learn from in an entire lifetime. These models have learned patterns of association from content where the associations were made by humans, and where the definitions of what counts as association and patterning have been given to them by their developers.
A model like that can reproduce these patterns. Because it has processed lots of images which humans have correctly identified as representing pandas, or riding a bicycle, or depth of field, the model can reproduce a depth-of-field photo of a panda riding a bike. Trained on enough examples of pre-existing human responses to questions similar to “Why can bees fly?” (“How do bees fly?”, “What physics lets bees fly?”, “Explain how bees fly.”, etc), it can answer plausibly when asked to “Explain how bees fly.” The frankly amazing output of AI models today is the result of them borrowing from millions (or even billions?) of human-years of associational work, content that resulted from humans giving meaning to the world around them and articulating that meaning.
The problem is that this is only human-level intelligence if we have an extraordinarily low bar for what counts as being human.
Meaning-making is what it means to be human for now
2022’s AI models are not intelligent in a way that makes them human.
They are still amazing because they can do so much of what humans have to do today and are thus powerful tools that humans are still learning how to use — but this doesn’t demonstrate their human-ness. Instead it demonstrates how much of human work is routine and uncreative. The junior graphic designer’s job of making digital mockups of the same shirt in 35 colourways is not creative work, it is routine work that should be done by machines. The first-year associate’s job of copying and pasting boilerplate clauses into a standard contract is also routine work that should be done by machines.
Machines in the form of AI systems (models + some kind of user interface) can now do much more of the routine, uncreative work that junior designers, first-year associates, and other downtrodden humans do. The AI systems that will succeed the AI systems of today will do even more of this drudge work, and they will do it more consistently, more cheaply, and more quickly than humans can.
Humans obviously can do many things which machines can do. The history of technology is humans making machines to replace this or that thing which humans previously did. What machines can do is, for now, by definition routine and uncreative — well-designed machines are good at being consistent in doing well-understood things.
What makes us human is not about doing routine, uncreative work that only reproduces what others have done before. What makes us human is our ability to do things which are not-yet-understood, which require us to be able to create meaning where there wasn’t meaning before. The meaning of “meaning” here is specific: Deciding or recognising that a thing or action or idea has (or lacks) value, that it is worth (or not worth) pursuing.
Creating meaning is how we solve the problem of deciding what to do and why. Machines may be good at figuring out how to achieve a given outcome, but so far only humans can decide that a particular outcome means something and is therefore worth doing. Meaning informs how humans act, all the way from the most trivial decisions (breakfasting on a soft omelet instead of scrambled eggs) to the most material and commercial decisions (spending billions on developing multitouch screens or AI models) to the most abstract decisions (the never-answerable question of what it means to live a good life).
Creating meaning is inextricably connected to self-directed intention. Random action is not intentional and cannot be meaningful. Being clear that only intentional action has meaning allows us to distinguish between the respective meaningfulnesses of [a rock falling off a mountain because a bobcat happened to kick it while running after a rabbit] and [a rock falling off a mountain when it was pushed by a human onto another human below] — even if the two rocks in question are the same one.
If a machine is trained on a dataset generated by human actions that were known in advance to be completely random, the signals or patterns it finds would have to be uninterpretable and meaningless by definition.
Human intentions are informed by context (history and social interaction). This looks superficially like how an AI model is trained on a large corpus of content. Intention is shaped by the specific context we are exposed to. Again superficially, this is like how the parameters of the training corpus shape the model. Because human intention is shaped by context, human actions are to some extent predictable. Predictability of action and causation is why we can have semi-coherent ideas of what it means to be part of a group (corporate or national culture) and why we can understand each other (shared language).
Consistently intentional meaningmaking generates recognisable patterns. Writing or making music or designing buildings or writing contracts with intent is a precursor for patterns in music, or architecture, or writing. This is why good writers, painters, coders, dancers, cooks, lawyers, judges can develop recognisable style.
The patterns AI models find in population data are patterns of meaning created by individual humans and their individual and collective activity. Even the pattern-seeking process requires human ability to create meaning — whether this is explicit (when deciding on the approach, parameters, and deployed algorithms of the machine learning system) or implicit (when human users indicate the quality of the system’s output by using it more in some ways compared to others). Machines cannot even find meaningful patterns in human-created content without humans to tell them which patterns are meaningful. In other words, AI models today borrow meaning from humans when they find and reproduce these patterns of meaning.
This is the only reason we can mistake AI model outputs for things with meaning that humans created. The model itself is not creating meaning in these outputs. The outputs have meaning that came from the humans who made the content from which the model learned, from the humans who wrote the prompts, and from the humans who designed the model’s training program and selected its training dataset.2 For now, AI models are just tools. Humans can use them to create meaning more easily (by offloading the drudge work), or in new ways, or both.
Self-directed intention is what distinguishes human intelligence from machine intelligence.3 A human can choose to act differently from how context would lead them to act. Humans can decide that an outcome is good and worth pursuing even if that the patterns of previous human activity would say otherwise. In other words, humans can intend to be unpredictable — the intentional unpredictability is the result of humans choosing to create new meaning for the outcomes they pursue and the actions they take to achieve those outcomes. This is how humans are able to make new things (like smartphones when only cellphones existed before, or a building with a diaphanous facade revealing internal structure instead of a massive facade providing structure4) or apply new meanings to things (like a urinal.
When machines are unpredictable, it is not because of self-directed intent. A machine’s unpredictability doesn’t come from the machine’s intention to create new meaning and thus be unpredictable. It comes instead from humans, who have built them so that their functioning produces unexpected effects. When humans intentionally build an unpredictable machine, the intentional unpredictability comes from the human builders (for instance, when humans build random number generators5). When humans unintentionally build an unpredictable machine, the unpredictability is a bug that has to either be fixed or worked around.
The imitation game doesn’t test human-ness
Alan Turing’s test is often used (in my view, mistakenly) as a way to think about a criterion for identifying when artificial human intelligence has been achieved. The test asks whether a human can distinguish the responses of an entity from that of another human. In the paper in which he describes the Turing test, he calls it “the imitation game.” If the human mistakes the entity’s responses for another human’s responses, then the entity in question is indistinguishable from a human. This indicates that the entity in question has the ability to think as a human would in processing and responding to information in a social interaction. If the entity is a machine, its performance in the imitation game would define it as a machine that can think like a human.
In his paper, Turing does not say that [being human] is the same thing as [being able to think and respond like a human would in a social interaction]. And the two things are different.6
The imitation game as described is interactional. What it means to give recognisably human responses depends at least to some degree on enculturation, which gives at least some commonality to the language or other medium in which stimulus and response occur. A connection can be drawn here to the training of AI models on corpora of content generated by humans — this gives the AI models language that has many similarities to the ones we speak, because they learned from content in the languages we speak. As described earlier, it is maybe not so surprising that we have managed to build machines trained on how humans express themselves, that seem to process and respond as humans do when we interact with them. So it is plausible to imagine that, from our human perspective, we have built machines that have cleared the bar of Turing’s imitation game.
Though the imitation game may be adequate for testing a machine’s ability to imitate a human’s interactions, it doesn’t test all of what makes humans human. An enormous part of life is about social interaction and is outward-turning. But not all of an individual’s life is about interaction. The inward-turning part is what gives individual humans the ability to be intentional ways that cannot be predicted by looking at the mass of humans they are part of.7 The inward-turning and outward-turning parts of the self are intertwined in reality but they are conceptually separable. In other words, what makes us human is not just how we interact with humans but also how we interact with ourselves.
Human-ness is (and should be) a moving target
What makes us human for now is the ability to say “I am human” (or any other statement which confers a meaning) even if no other humans say so.
This is an act of meaningmaking, and that it is both something done in relation to others (outward-turning) but also something done by the individual (inward-turning) is illustrated by individuals who have asserted their humanness first to themselves and then to others. An example is an artist who makes work that is new even if no one seems to like it. For other examples, you could look to any of the many people who rejected racial segregation policies in the American South. Sometimes, the individual meaningmaking becomes contagious and changes meaning in the broader system, as it did through the lawsuits that eventually did away with racial segregation policies in America. But the ability to make meaning (to say “This has worth for these reasons”) is not inherently tied to saying so to other people — that’s just when and how other people know that meaningmaking has happened.
If human-ness is about meaningmaking that can consider a situation and do something different, then human-ness is normative and changeable — human-ness should be aspirational, a moving target. Deciding that human-ness should be purely imitative is to set being human at the level of the ability to simply reproduce patterns found somewhere else, at the behest of someone else, and no more. Human-ness would be inherently static if that were true. This is itself a normative position.
There is nothing to stop a human from adopting that position other than arguments to the contrary, that we should want more for human-ness now that our machines are getting good enough to justify us raising the bar for being human. One such argument to the contrary is that the logic of imitative human-ness also leads inexorably to (in other times and places, but also in this time in some places) concluding that it is correct and unchangeable that what makes someone human enough to vote (or go to school) is the fact of being male. Or something similarly insupportable.
What counts as a norm — which is a pattern of meaning that has become widespread enough for long enough to be taken for granted — changes over time as things change. What makes us human changes over time, in relation to what we choose to set ourselves apart from. Our ability to individually or collectively upgrade what it means to be human as time goes on and the context changes is what makes us human. Again, this is the same thing as the ability to make and give new meaning instead of simply borrowing and reusing old meaning.
I should say explicitly that despite all I have written so far I am not saying that I believe there is something fundamentally different between a sand machine and a meat machine. There is probably no fairy dust which makes humans intrinsically different from computers, so the future may hold machines that can also make meaning. At that point, we will probably want to upgrade our definition of human-ness to something else that may not be conceivable at the moment. But there is no way to know for sure. That we are meat machines means that for now the scale of human biological complexity still outstrips computer complexity, and I think the jury is still out about whether complexity creates its own qualitative difference at scale.8
So if machines right now can at best borrow meaning from humans, why are so many people excited that we are standing on the edge of machine intelligences that are profound enough to be human? My hypothesis: It’s because those people have fallen out of the habit of explicitly using the meaningmaking ability that we all have — but that is for another essay.
This is the third of Arthur C. Clarke’s so-called laws of futures thinking.↩︎
Which is how unconscious algorithmic bias arises. ↩︎
Thanks to Dan Schrage, who reminded me about John Searle’s argument (illustrated with the Chinese Room thought experiment) that simulation of intelligence is not the same thing as having a mind like humans do, and thus forced me to go look up again the large literature on intentionality.↩︎
Thanks to Paul Henninger for an unexpected conversation about what Mies van der Rohe was trying to do in his designs for the Seagram Building. ↩︎
Making a machine that is intentionally unpredictable is predictably difficult because machines are (so far, and possibly forever) unavoidably deterministic and thus predictable. Most random number generators actually generate pseudorandom numbers, which come close to being random but aren’t actually. For this reason, attempts to build good random number generators often resort to drawing randomness not from the machine but from some physical process which is believed to be chaotic and unpredictable, like the changing fluid patterns in lava lamps. ↩︎
Thanks to Nikete della Penna, who bluntly and vigorously reminded me that it would be inevitable for my argument to be considered vacuous and repetitive if I didn’t explicitly address how it is distinct from the argument Turing made about whether machines think.↩︎
George Mead (and the symbolic interactionist school of sociology) distinguished between the socially formed “me” and the individual “I” that forms in response (i.e., reflexively) to the “me” that make up each person. They form in relation to each other, but are conceptually separable. The “me” seems to be what machines can now imitate — this essay is trying to make an argument that part of what’s left in the “I” is the ability to make meaning. These ideas can be found in the volume titled Mind, Self, and Society.↩︎
Thanks to Erik Garrison for pointing out that complexity at scale (of the sort that biological systems like humans already possess) may itself be fairy dust, albeit of a different sort from the type of fairy dust that seems to be talked about a lot.↩︎