Not-knowing discussion #5: False advertising (summary)
31/5/2023 ☼ not-knowing ☼ ii ☼ iisummary
This is a summary of the fifth session in the InterIntellect series on not-knowing, which happened on 18 May 2023.
Upcoming: “Actions and results,” 22 June 2023, 2000-2200h CET. The sixth session in the series is about what happens when we admit the possibility that there are actions to be taken that we don’t know about yet, and that they might produce outcomes that we haven’t thought about yet. These two forms of not-knowing are the source of new techniques for painting, new ways of making vaccines, and new business models — among many other things that are new. How do new technologies and tools change the kinds of actions we could take in any given situation? How does the increasing complexity and interconnectedness of the world change the types of outcomes we have access to? And how can we think about outcomes that are created or modified by conditions beyond our direct control? More information and tickets available here. As usual, get in touch if you want to come but the $15 ticket price isn’t doable — I can sort you out.
False advertising
Reading: Overloading and appropriation.
Participants: Sam T., Indy N., Mike W., Travis K., Chris B., George M., Mackenzie F.
We began from the observation that there are two types of inaccuracy in how we talk about forms of not-knowing: Overloading (for risk) and appropriation (for uncertainty).
- We overload the word “risk” by using it to refer to many different situations of not-knowing, nearly all of which are not formal risk. Here, overloading has similar sense to how it is used in computer programming.
- We appropriate the word “uncertainty” by using it to implicitly refer to Knightian uncertainty when we actually are referring to formal risk. Here, appropriation has the sense of using the word “uncertainty” in a way that does violence to its meaning as unquantifiable not-knowing about a situation (i.e., Knight’s definition).
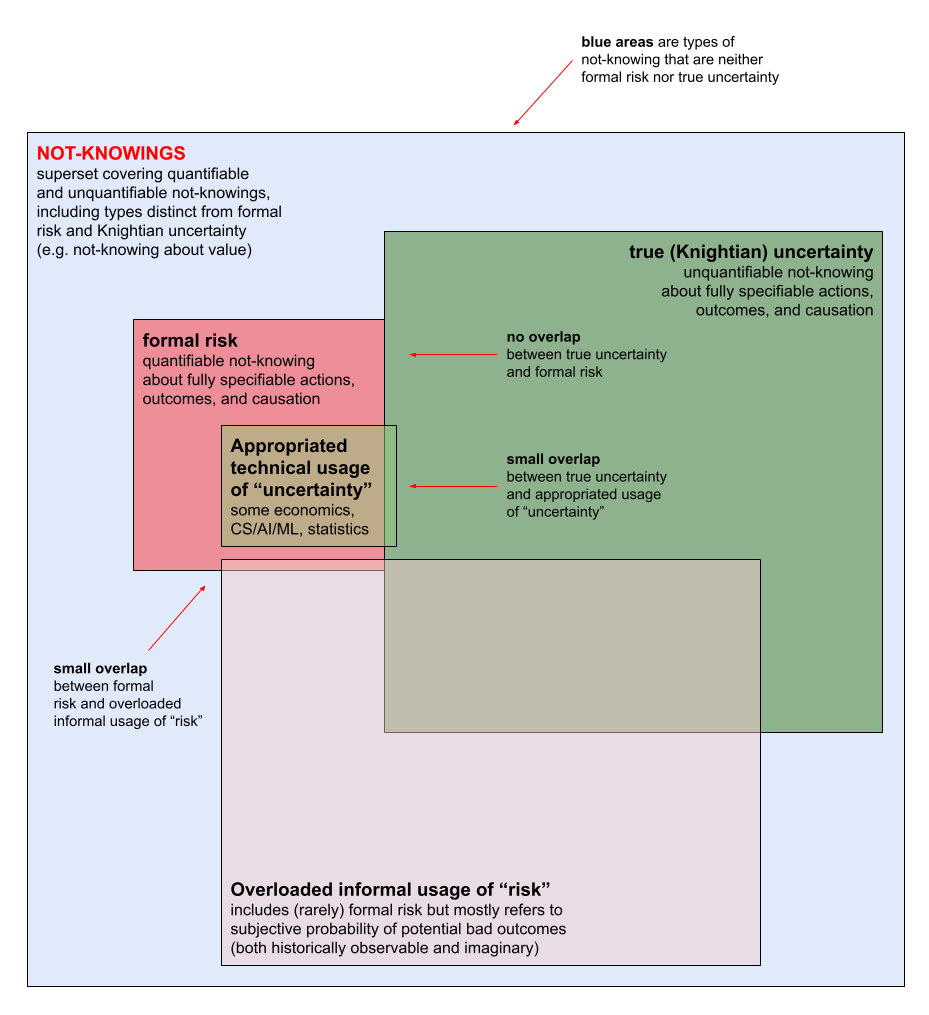 A visual representation of overloading and appropriation in how we talk about forms of not-knowing.
A visual representation of overloading and appropriation in how we talk about forms of not-knowing.
Why do we overload and appropriate? Overloading takes scary non-risk forms of not-knowing and labels them all as “risk,” which is quantifiable and manageable. Appropriation takes specific, manageable types of not-knowing and labels them as “true uncertainty,” suggesting that true uncertainty is now manageable. Both forms of inaccurate usage provide false comfort by creating the impression that unknowns are more manageable and controllable than they actually are.
This session focused on appropriating uncertainty (the previous session was about overloading risk). The specific context for exploring appropriation of uncertainty was machine learning (ML) and the growing number of techniques developed to deal with partial knowledge inherent in ML models. Then, as it usually does, the conversation went in many unexpected directions.
Discussion highlights
- Aspects/types of what’s called “uncertainty” in AI/ML (a non-exhaustive list). Some of these types are not truly uncertain (hence appropriative)
- Uncertainty from poor data quality: Model builders and users need to understand the quality of the data (e.g., incomplete or otherwise biased datasets) on which models are built so that they can interpret the outputs of these models. This may not be true (Knightian) uncertainty, especially for datasets where the range of possible values is constrained by design to a fully specifiable set.
- Uncertainty from model opacity: The trained model itself introduces uncertainty, especially when it is a black box, because the mechanism by which model outputs are produced is not clearly understood. Again, this may not be true uncertainty, though the underlying model when revealed may prove to be beyond human capacity to comprehend.
- Uncertainty from inherent ambiguity in data: This seems like a type of epistemic true uncertainty. This type of uncertainty seems correlated with the requirement for representing complexity in the data domain. Concepts and distinctions ramify and increase in number as the complexity of what needs to be represented/communicated increases. Names of colours and names for numbers (countable units) were two examples that came up in discussion. This is related to the underlying problem of how people who don’t share the same subjective reality can communicate. This pattern (complexity of terminology being driven by requirement for representing/communicating complexity in a domain) also seems clearly connected to the need for more nuanced ways to describe and talk about about different types of not-knowing.
- Uncertainty from subjectivity of experience: This seems like another type of true epistemic uncertainty. Current ML approaches depend (either implicitly or explicitly) on analyses of the names given to things/concepts. This conceals true uncertainty about models that results from the distinction between perception of phenomena and names for phenomena, the fact that language (in the form of names for things) partly determines what we perceive, and the fact that different individuals have different ranges of perception (the idea of an individual- or species-specific sensorium or gamut).
- Humans seem to have a deep and instinctive need to both know things and be certain of them. At the same time, we are increasingly perceptually and cognitively overloaded by information. This may be what leads humans to be increasingly willing to relinquish to machines the responsibility for and the task of knowing things and making sense of those things. This may also be why humans have strong implicit beliefs about certainty and the possibility of being certain, and why we find it so difficult to change those beliefs even when faced with evidence that such beliefs are not consistent with reality. This cluster of observations is probably connected to the complicated emotional and physiological context for how we experience and think about situations of not-knowing, and the fact that cognition alone is not enough to overcome the mandates of the body.
- Current machine systems seem particularly good at dealing with human failings that are not about uncertainty (bias, laziness, inconsistency), while humans seem particularly good at dealing with some types of true uncertainty (unpredicted situations that require in-the-moment sensemaking). Example: Self-driving cars and their failure modes.
- The current default approach to partial knowledge appears to be make arbitrarily precise quantifications of expected values and their probabilities of occurrence. These quantifications often begin as ways to communicate situation assessments and promote transparency or accountability. However, they eventually become entrenched as forms of false knowledge that drive questionable decisionmaking — “quasi-science” or “pseudo-science.” This is also related to “risk theatre” and “innovation theatre,” (i.e., performative actions done for the sake of something believed to be valuable that may have little or no actual effect). Examples:
- Finance: Making up probabilities for outcomes and expected values when computing future returns to financial investments.
- Public health: Making up probabilities and expected values when deciding whether or not to shut down international travel at the beginning of the Covid-19 pandemic.
- Operations management (broadly): Making up probabilities when deciding on the level of approval authority required for taking actions that may have negative consequences. This happens in military operations, forestry and land management, civil aviation, and many other domains.
Fragmentary ideas/questions which seem valuable
- What would an organization’s uncertainty management function look like, and what tasks/actions would it perform? The risk management function is now ubiquitous in large organizations, and has an extensive set of sophisticated quantitative techniques as its toolkit (e.g. cost-benefit analyses and expected value calculations). However, the toolkit for managing non-risk forms of not-knowing seems restricted to mysticism and/or surrender to randomness — e.g. human oracles, haruspication, tea leaves, bone reading, and many other forms of ancient and modern divination. Are there other approaches to managing non-risk not-knowing? (VT’s comment: This project on understanding not-knowing is designed to develop a broader toolkit for relating to and working with non-risk forms of not-knowing.)
- What does capacity building and a maturity model for dealing with not-knowing look like? (VT’s comment: My preliminary hypothesis is that such a model begins from clarity about different types of not-knowing, and that capacity for dealing with not-knowing is built up progressively and slowly, through experience.)
- Is not-knowing what makes something really alive/dynamic (because of the possibility of unpredictability and emergence)? And is certainty therefore only possible when something is dead/static?
- Can uncertainty itself be dynamic or static? What would such a distinction mean?
- Is certainty ever possible?
- What is the opposite of not-knowing? Is it knowing? Is it certainty?
- What would good uses of AI/ML which acknowledge true uncertainty look like?